|
Author: Bailey DeBarmore
In a previous post, I talked you through how to get your data clean in Excel before importing to Stata, SAS, or R [read that post here]. The next step is to import that data and start creating variables you need for analysis and running descriptives. I'll go through how to import your data in this post.
Feel free to post questions in the comments! Stata
The best way to import data into Stata is to use the menu and have Stata do it for you. Once you import the data, you'll be able to copy the commands you need and save to your do file for the future. So I'm going to walk you through how to use the click menu rather than sharing syntax that changes from version to version in Stata.
Before we do that, let's talk about setting the working directory. If you are pulling files from multiple locations on your computer, you'll want to save the code (cd) to your do file so you can move around. We'll first use the click menu to produce the code. 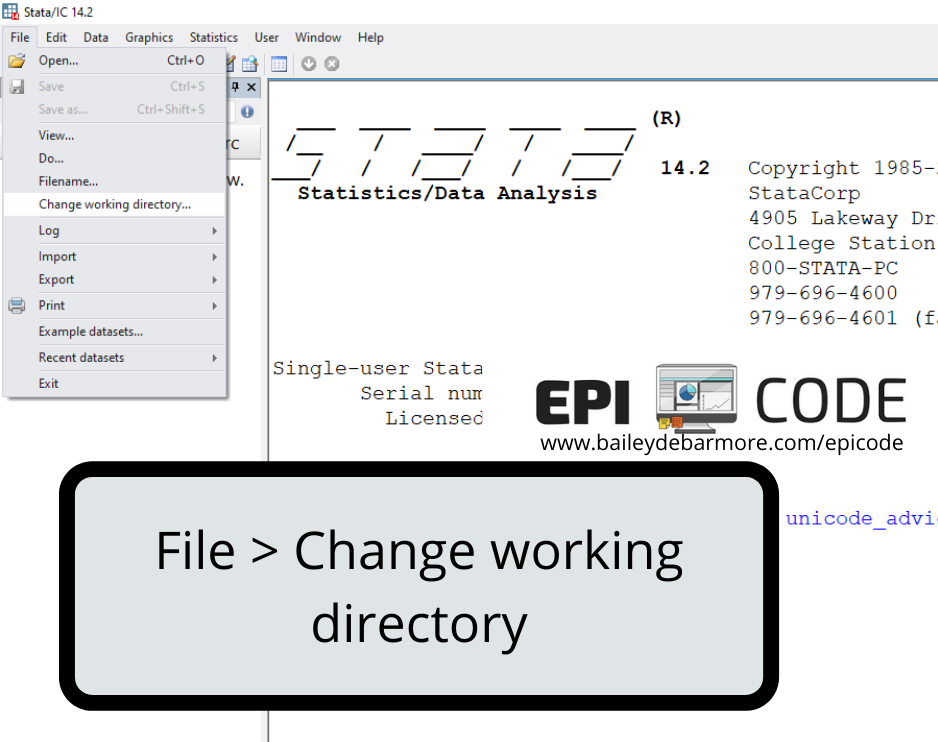
Type cd followed by the path name in double quotes.
cd "C:\Users\bailey\EPICODE" 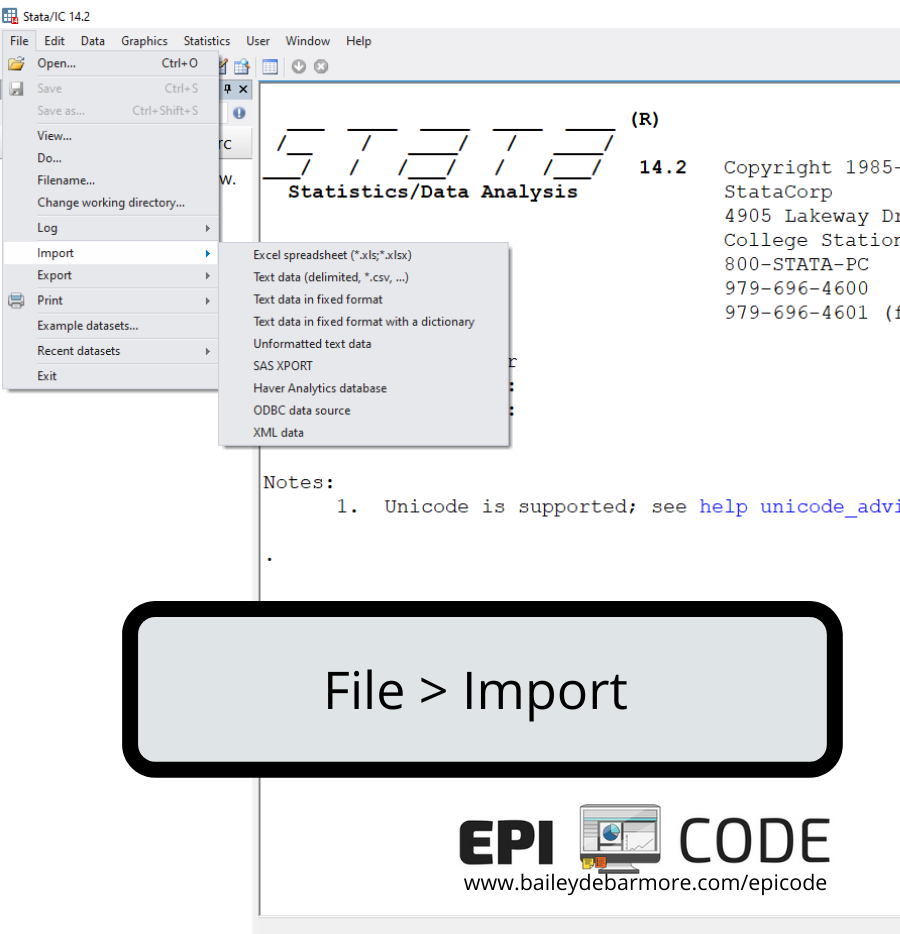
Excel file (.xls, xlsx)
If your data is in an Excel file, you can import a specific worksheet using File > Import > Excel spreadsheet. When the new window opens, click BROWSE to find your Excel file. Then, fill out the correct options. You'll see a preview of your data. You want to make sure you select 'first row as variable names' if that applies, and decide whether you want to preserve case or not. Since Stata is case-sensitive, if you named your variables like Gender, SchoolID, etc. you will need to always refer to them that way (not gender, schoolid). If you decide you want to do all lowercase or all uppercase, you can select those options in the dropdown. When you're ready, hit OK and you should see the variable window populate. Final step is to go to File > Save as and save this data set as a Stata dataset (.dta) - you don't want to import it every time you need to work on it. 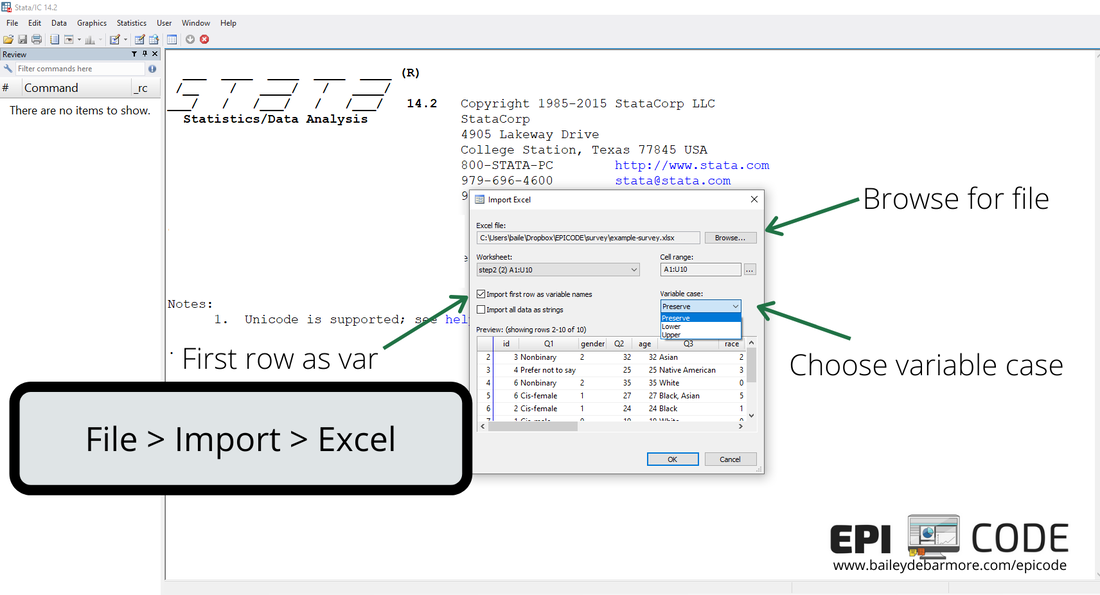
Link to Stata Manual for import excel I'm using Stata14 and when I did the click menu steps above to import my data, the resulting syntax was: import excel "C:\Users\bailey\EPICODE\example-survey.xlsx", sheet("<sheetname>") firstrow
<Location> is the C:\User path where the xlsx file can be found, and dataset.xlsx is the Excel file name.
<Sheetname> is the name of the specific worksheet in my Excel document The option firstrow told Stata to import the first row as variable names If you're importing multiple files, you can copy this syntax into your do file and change the path name/document name, and then save to easily run these commands over and over again. This is useful if you are appending or merging multiple files. import excel "<location\dataset1.xlsx>", sheet("<sheetname>") firstrow
Delimited file (.csv, .tsv, .txt)
Delimited files have information in columns and rows seaparate by 'delimieters' which are often a comma (csv), tab (tsv), or comma, tab, space, linebreaks, and others (txt). Often you may have a dataset that is a csv but opened in Excel. Or you may have one that opens in a text file. Either way, when you choose File > Import > Delimited, Stata will automatically identify the delimiter for you. It will also detect if you have variables in the first row or not. Similar to the Excel import, you can choose to preserve SnakeCase variable names or not. 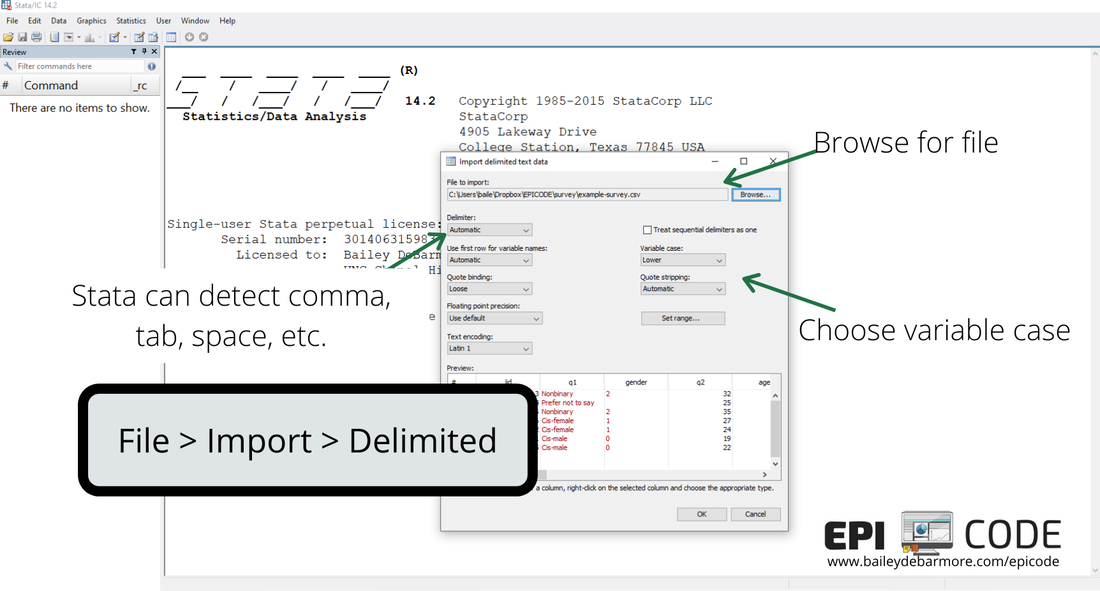
Link to Stata Manual for import delimited When I import a csv to Stata14, I get the following syntax that I can save in my do file for later. There are no quotation marks and you don't include the <>, those are just here as an example. import delimited C:\Users\bailey\EPICODE\example-survey.csv
<Location> is the C:\User path where the csv file can be found, and dataset.csv is the file name.
If you're importing multiple files, you can copy this syntax into your do file and change the path name/document name, and then save to easily run these commands over and over again. This is useful if you are appending or merging multiple files. See below how I change the working directory with a cd command without ever leaving my do file. cd "C:\Users\bailey\EPICODE"
SAS XPORT (.xport)
I don't have a screenshot for importing a SAS XPORT file but it follows the same logic as the Excel and delimited files. Go to File > Import > SAS XPORT, browse for your file, select any options, and press OK. Then File > Save As to save it as a Stata dataset (.dta) Link to Stata Manual for import sasxport SAS (.sas) If you need to import a SAS data file into Stata and it is .sas (not XPORT) then the best way is to export it from SAS as a .dta file (which is the Stata dataset file type). Just as SAS has a click menu option for import, you can also use it for export (see images and code below). Then you can easily open it in Stata by double-clicking the file in your folder or going to File > Open and browsing for it. 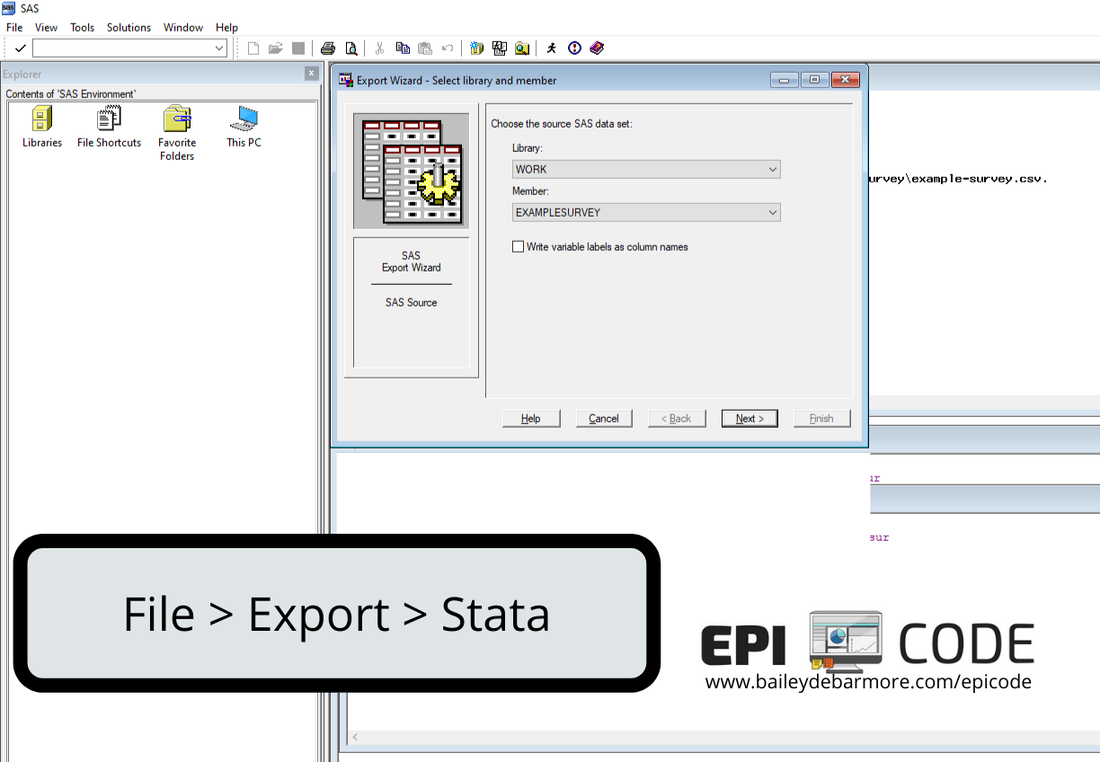
PROC EXPORT DATA= WORK.EXAMPLESURVEY
If you choose to have SAS save the export code, you'll get code like the one above.
The key elements are
SAS
Usually, the best way to import data into SAS is to use the Import Wizard and have SAS do it for you. During the import process, you can choose to have SAS save the commands in an Editor that you can access and save the code for later. I provide screenshots below on how to use the Import Wizard and the resulting code for you.
Before we get into that, be sure you've run your libname statement which tells SAS where to go look for data. I typically like to have a lib for where it will pull data from, where it will put data, and where it will save files. Type 'libname', then name the lib, and then encase the path in double quotes. libname data "C:\Users\bailey\EPICODE\data" 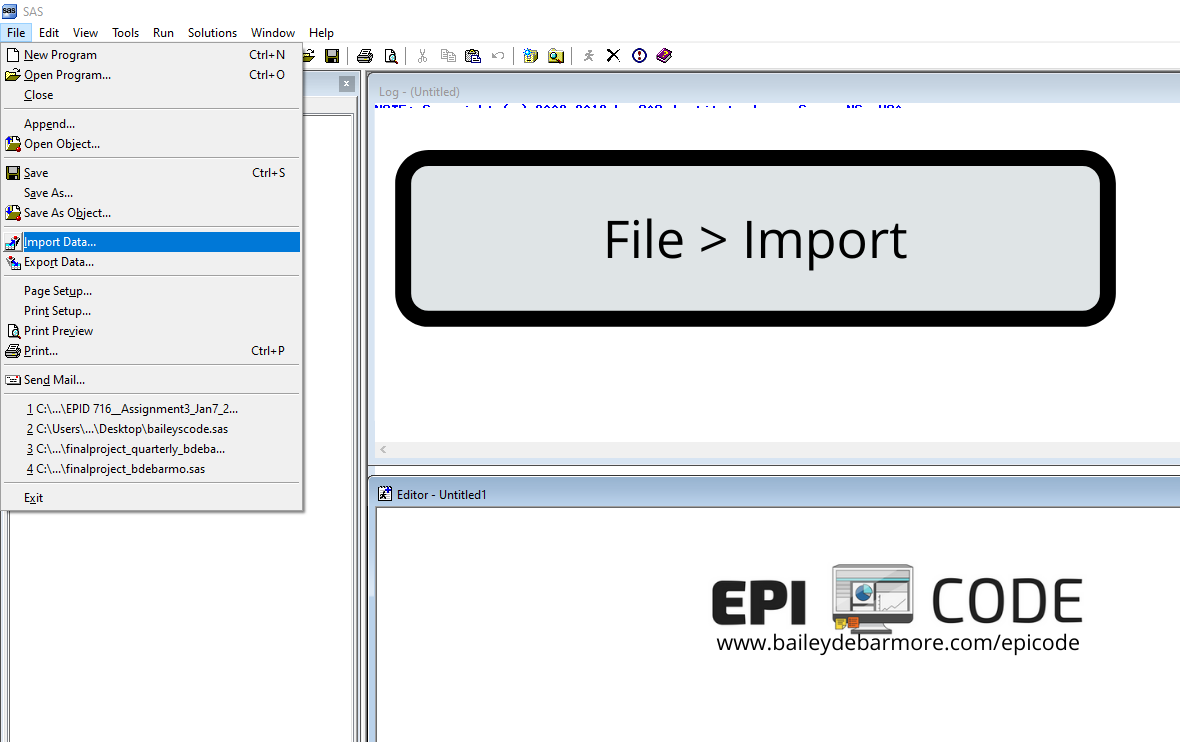
Excel files (.xls, .xlsx)
Using File > Import and then selecting Excel in the dropdown, you can import an Excel file into SAS. When you go to browse, make sure that in file type you have "All Files" or specifically "xls" or "xlsx" selected so that your file of choice shows up. In the final screen, if you select a location for SAS to save an editor file, you will get code like the code below that you can reuse later. If you're having trouble with the import wizard (like you're getting an error that says it cannot connect to MS Excel) try running the code provided below. 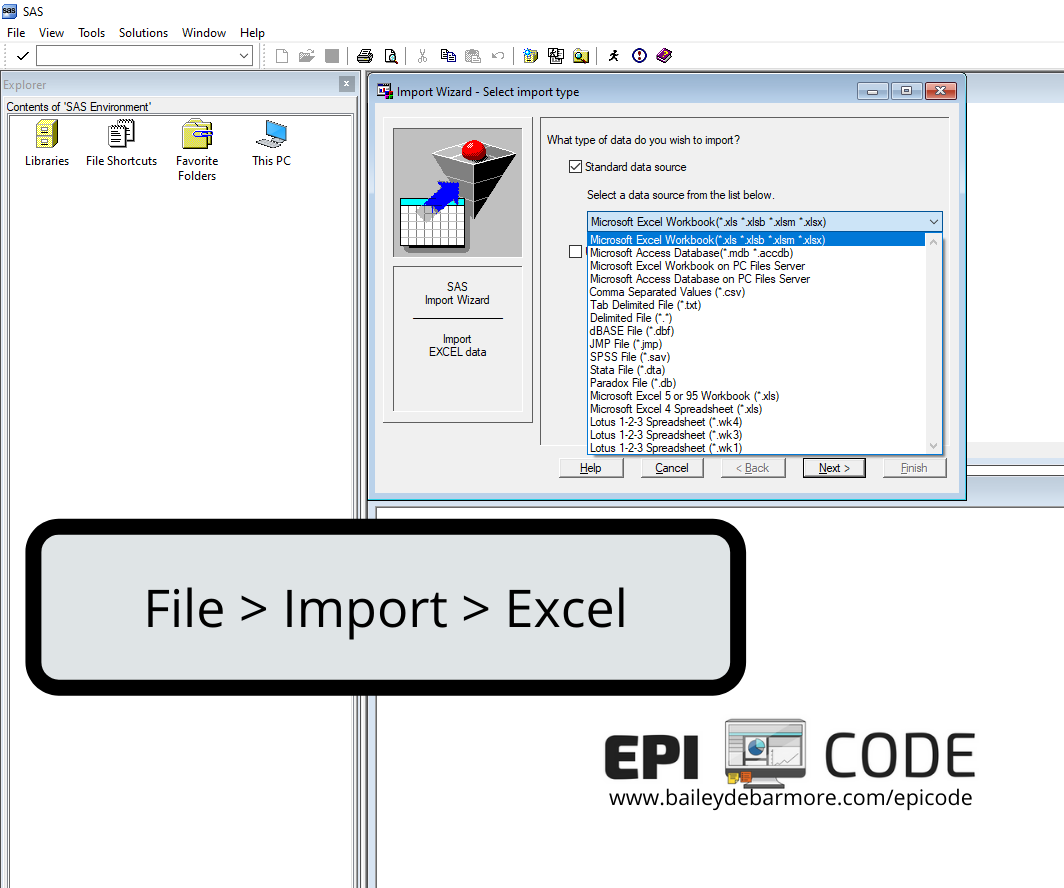
PROC IMPORT OUT= WORK.examplesurvey The key elements are
When you're done importing, run a data step to save the data in your lib of choice.
Delimited files
Using File > Import and then selecting CSV in the dropdown, you can import a csv file into SAS. In the final screen, if you select a location for SAS to save an editor file, you will get code like the code below that you can reuse later. 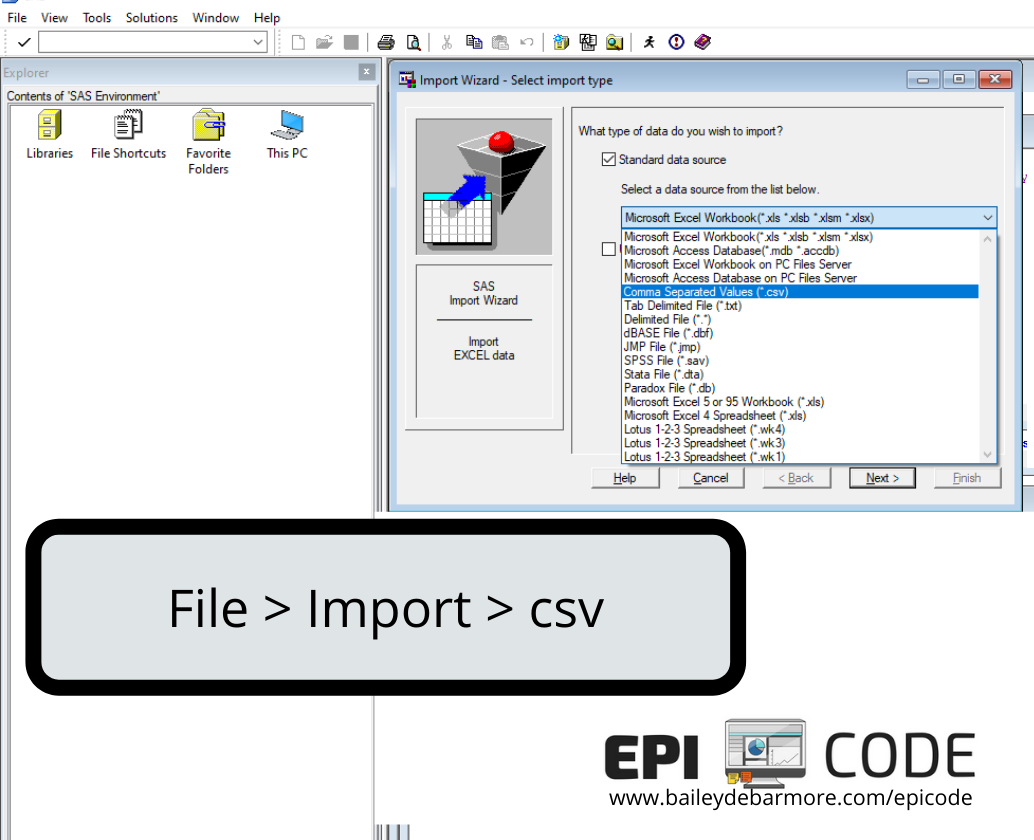
PROC IMPORT OUT= WORK.examplesurvey
The key elements are
If you're importing a Delimited (.) or Text (.txt) file then instead of choosing CSV in the drop-down, select those options. They will replace the CSV in the DBMS part of the PROC IMPORT statement. When you're done importing, run a data step to save the data in your lib of choice. In the example above I have LIB.examplesurvey where LIB is just a placeholder for whatever you named your lib. If we're following my libname statements from the beginning of this section, it would be data.examplesurvey.
Stata file (.dta)
Using File > Import and then selecting Stata in the dropdown, you can import a Stata data file into SAS. In the final screen, if you select a location for SAS to save an editor file, you will get code like the code below that you can reuse later. 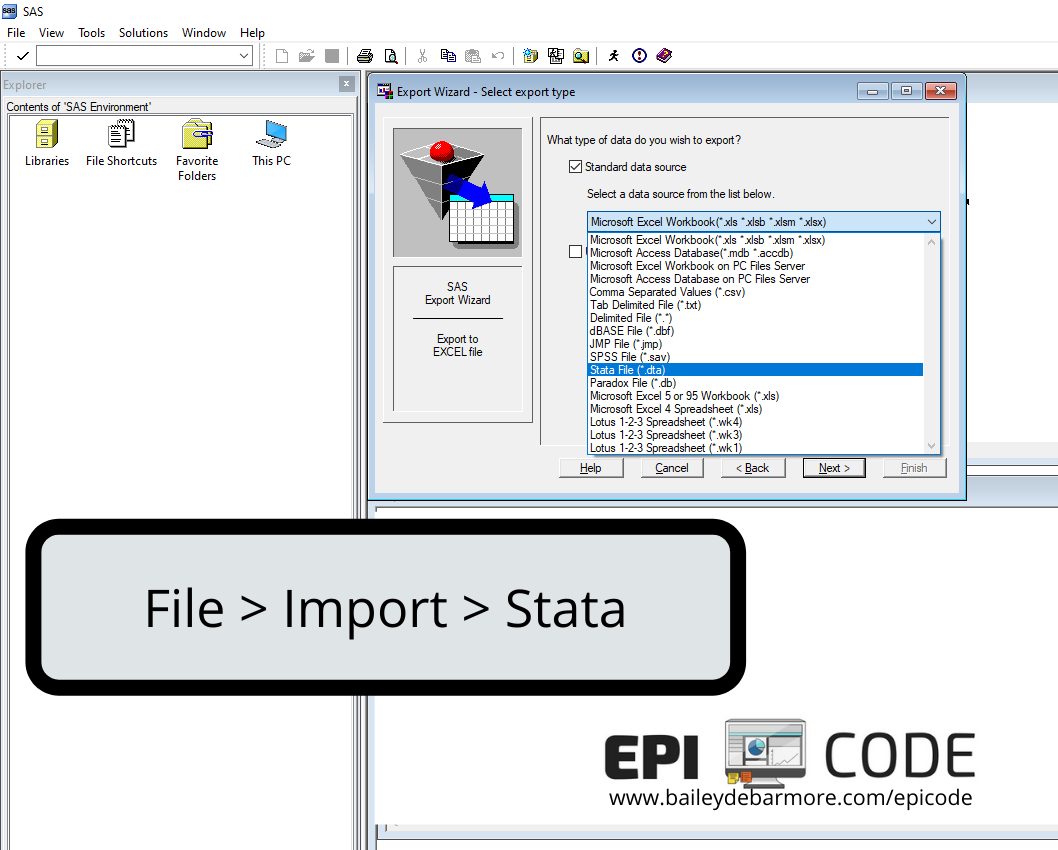
PROC IMPORT OUT= WORK.EXAMPLESURVEY2
The key elements are
PROC IMPORT statement: what will you name your new SAS data set? Do you want it to be in the work library or another lib? Make sure you have libname statement previously to establish that library in that SAS working session.
R
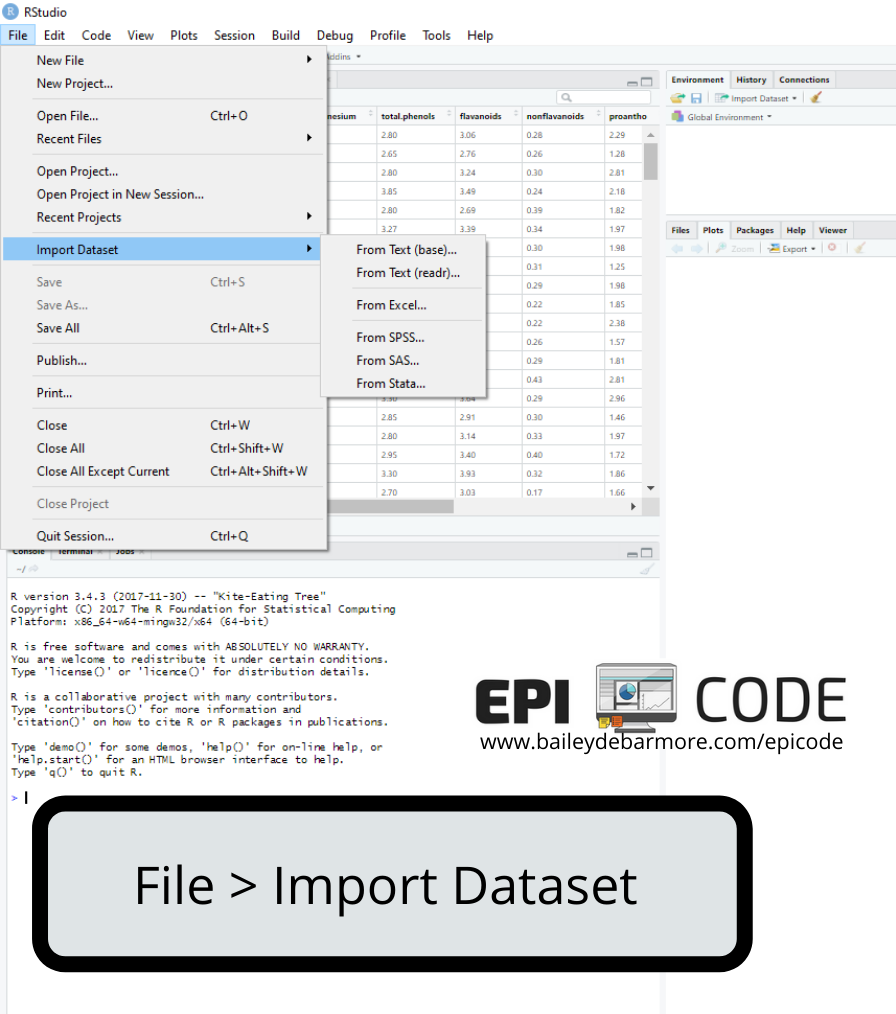
Just like with SAS and Stata, you can use the click menu to import data. Go to File > Import Dataset and select From Text (base), From Excel, From SPSS, From SAS, From Stata. The code will appear in your console and you can save it in your script.
To set your working directory in R, use 'setwd' and enclose the path in quotes and parentheses. If you have data in R format already (.rds) you can read in using readRDS and save out using saveRDS. Filenames also need to be in quotes.
If you set your working directory (wd) then in the following examples, you would be able to simply refer to the file name rather than the full file path if you are typing out your code. Otherwise you can always specify the full path, especially if you're pulling in data form multiple locations. In addition to the code below, you can use the click menu to set your working directory. Go to Session > Set Working Directory > Choose Directory. setwd("C:/Users/bailey/EPICODE") 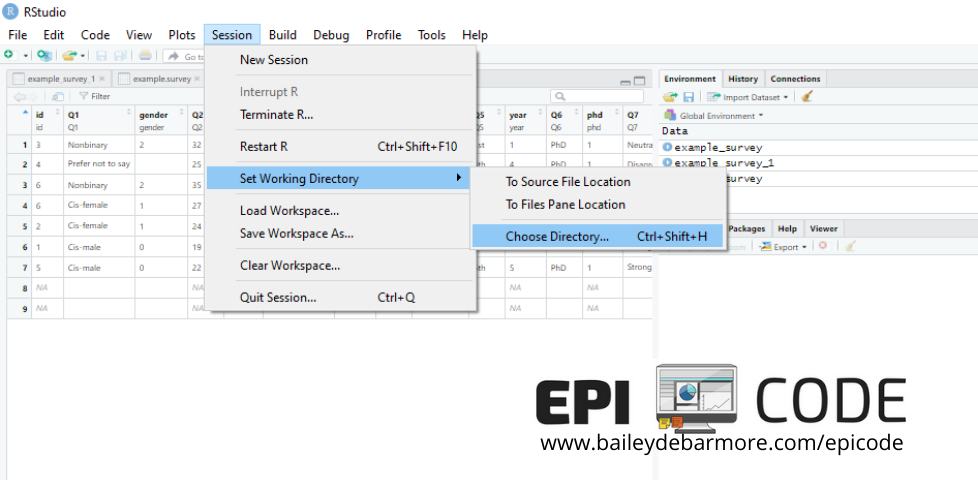
To read in data in other formats, you can use read.csv(), read.xls(), read.spss(), read.dta(), read.delim(), read.table(). There are also packages like haven that you can use to read SAS files (read_sas()). Haven will also read Stata files (.dta) and other file types.
Excel (.xls, .xlsx)
To import my xlsx file, I used File > Import Dataset > From Excel. Then I browsed for my file, and checked the options in the bottom right - first name as variables, correct sheet, etc. The code R used was from the readxl package, using read_excel, because base R only has a function for xls files, not xlsx. In the code below, I've read in my file example-survey-1.xslx to R as the object example_survey_1. library(readxl) 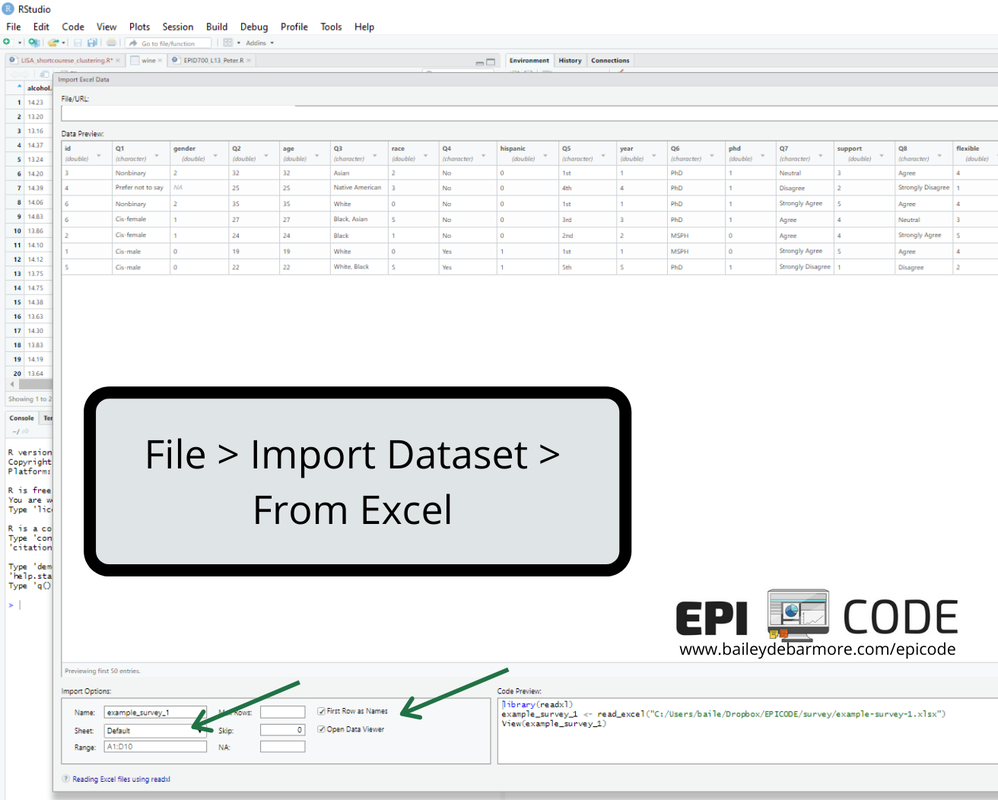
Delimited files (csv)
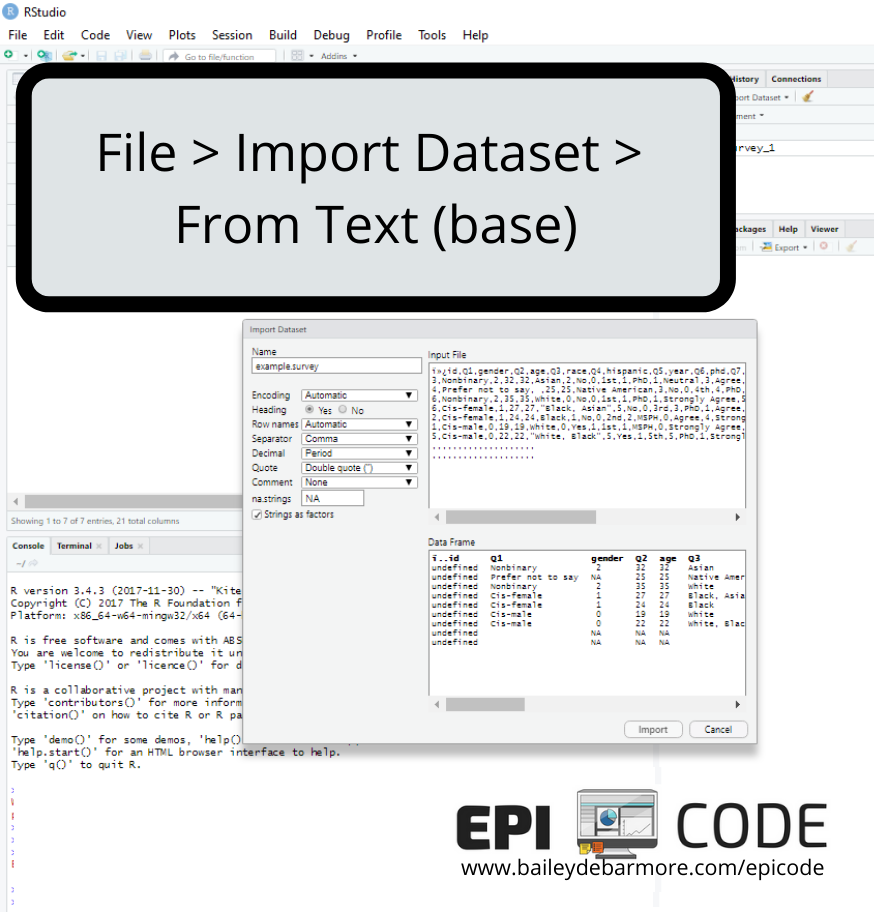
To import my csv file, I go to File > Import Dataset > From Text (base). Immediately, the file browser comes up. When I select my file, I can check the options - such as first row as variable names, and look at the preview. The resulting code in my console is:
example.survey <- read.csv("C:/Users/bailey/EPICODE/example-survey.csv")
R simply used the base R function read.csv to read in the file and named it with the same name.
SAS (.sas, .sas7bdat)
To use the haven package, install it, load it with the library function, and then use read_sas() and the file extension .sas7bdat to read it into R. You can also use File > Import Dataset > From SAS and R will produce the code for you. install.packages('haven')
Stata (.dta)
To use the haven package, install it, load it with the library function, and then use read_dta() and the file extension .dta to read it into R. You can also use File > Import Dataset > From Stata and R will produce the code for you. install.packages('haven') 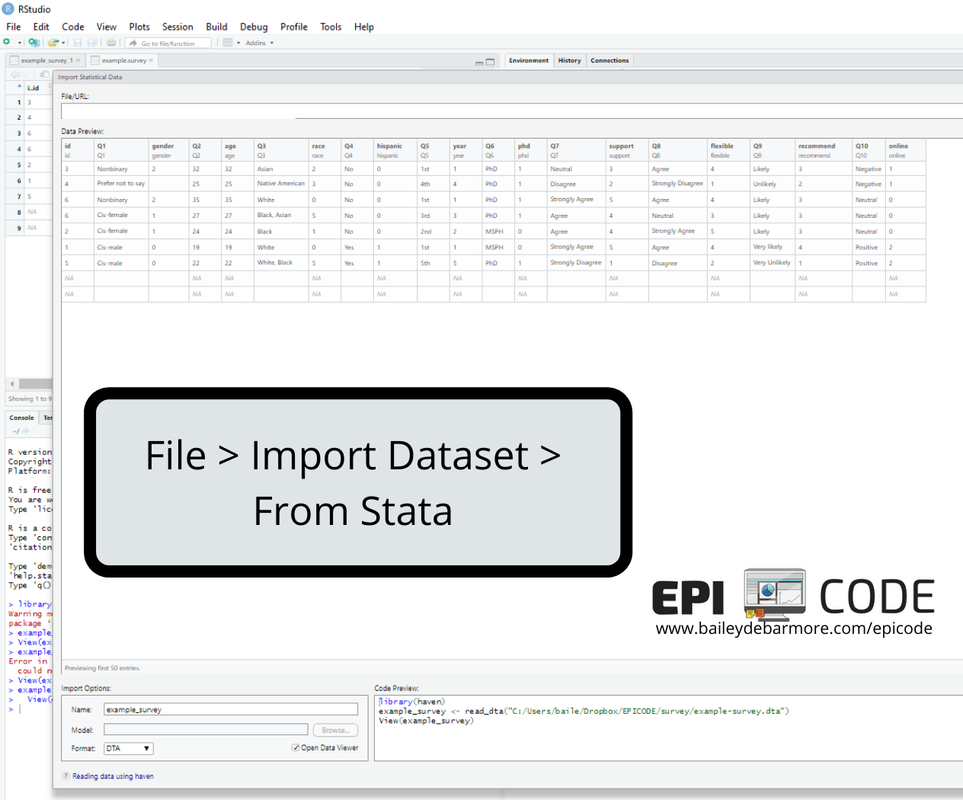
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |

Practical solutions for conducting great epidemiology methods. Transparency in code. Attitude of constant improvement. Appreciate my stuff?

All
March 2021
|


 RSS Feed
RSS Feed